یکی از ابزارهای مفید برای تجزیه و تحلیل اطلاعات احتمالی و یک طرفه، فیلترهای بلوم است. این فیلترهای بلوم ابزاری هستند که ما را در تجزیه و تحلیل مقادیر زیادی از اطلاعات احتمالی تسهیل می کنند. این به منظور دانستن اینکه آیا یک عنصر یا داده بخشی از یک مجموعه است یا خیر. این تابعی است که در مواقعی که باید حجم زیادی از داده را مدیریت کنیم بسیار مفید است. به خصوص زمانی که چنین اطلاعاتی نمی توانند به سرعت به صورت دستی پردازش شوند.
به همین دلیل است که به لطف فیلترهای بلوم، ارزهای دیجیتال مانند بیت کوین عملکرد کیف پول SPV را دارند. اما ما این ویژگی را در ارزهای رمزنگاری شده مانند اتریوم نیز مشاهده می کنیم که به شما امکان می دهد اطلاعات را در بلاک چین خود به طور موثر جستجو کنید.
و این به لطف این واقعیت است که فیلترهای بلوم به ما اجازه می دهند فقط دو نتیجه داشته باشیم: مثبت کاذب یا منفی . به این معنا که با اجرای فیلترهای بلوم می توان به سرعت و کارآمد دانست که آیا عناصر خاصی ممکن است در حافظه وجود داشته باشند یا اینکه قطعا وجود ندارند. نتایج مثبت کاذب این احتمال را ایجاد می کند که یک عنصر یا داده می تواند بخشی از یک مجموعه باشد. در حالی که نتایج منفی به طور قطع نتیجه می گیرد که عنصر یا داده در مجموعه ارزیابی شده گنجانده نشده است. این ابزار در عین حال به ما اجازه می دهد تا به طور کامل منفی های کاذب را رد کنیم، که تجزیه و تحلیل داده ها را تا حد زیادی تسهیل می کند.
اما چه چیزی منجر به ایجاد فیلتر بلوم شد؟ رابطه اینها با دنیای بلاک چین چیست؟ خوب، در ادامه همراه ما باشید..

منشا فیلترهای بلوم
فیلترهای بلوم در دهه ۷۰ توسط توسعه دهنده Burton Howard Bloom طراحی شدند. بلوم که فارغ التحصیل رشته علوم کامپیوتر از MIT است، این فیلترها را به عنوان یک ساختار داده احتمالی کارآمد در فضا طراحی کرد که به شما امکان می دهد بررسی کنید که آیا یک عنصر یا داده بخشی از یک مجموعه است یا خیر. هدف پس از ایجاد آن، ایجاد یک ابزار طبقهبندی دادهها از طریق اعمال توابع هش بود که یک نتیجه یا یک شناسایی را برمیگرداند. در عین حال، این امکان را به شما می دهد که اگر عنصری که بررسی می شود بخشی از مجموعه نیست، یا نشان می دهد که احتمالاً در آن قرار دارد، با اطمینان پاسخ دهید.
بنابراین، طراحی این فیلترهای بلوم امکان مدیریت پایگاه های داده یا اطلاعات بزرگ را با سرعت بالا فراهم می کند. و در عین حال از فضای ذخیره سازی استفاده بهینه می شود. این به این دلیل است که فیلترهای بلوم نیازی به ذخیره خود عناصر یا داده ندارند، بلکه فقط بررسی می کند که آیا آنها در مجموعه هستند یا خیر. یک عملیات داده فقط خواندنی که عملکرد بالا و قابلیتهای پردازش اطلاعات عالی را ممکن میسازد.
فیلترهای بلوم چگونه پیکربندی می شوند؟
فیلترهای بلوم دارای چیزی هستند که به عنوان ساختار داده آرایه ورودی شناخته می شود . این آرایه دارای طول یا ظرفیت ذخیره سازی به اندازه لازم است. این به این معنی است که هنگام ساخت یک فیلتر بلوم می توانید تعیین کنید که طول فیلتر چقدر باشد. تعریف اینکه چه تعداد ورودی به ساختار داده پایه اضافه خواهد شد و چه تعداد توابع هش در فیلتر مورد استفاده قرار خواهند گرفت و هر یک از این ورودی ها را مرتبط می کند.
به همین ترتیب، در زمان طراحی آن باید در نظر گرفت که محدوده توابع هش باید از ۰ شروع شود و به تعداد ورودی های موجود منهای ۱ ختم شود. به عبارت دیگر، اگر فیلتر بلوم برای ۱۰ ورودی طراحی شده باشد، با عدد ۰ شروع و به عدد ۹ ختم می شود. اگر فیلتر بلوم برای ۲۰ ورودی طراحی شده باشد، فیلتر بلوم از عدد ۰ شروع و به عدد ۱۹ ختم می شود. یک روش طراحی محاسباتی که به دنبال به حداکثر رساندن منابع پردازش فیلتر است.
به همین ترتیب، هنگامی که مجموعه ورودی های موجود تمام مقادیر خود را در ۰ پیدا می کند، به این معنی است که داده ها در فیلتر بلوم نیستند. پس خالی است. بنابراین لحظه ای که شروع به اضافه کردن داده ها یا عناصر به فیلتر می کنید، اطلاعات از طریق توابع هش مربوطه منتقل می شود که اطلاعات مذکور را در محل مربوطه در فیلتر بلوم قرار می دهد. بنابراین این مکانها مقدار ۱ را منعکس میکنند و نشان میدهند که حاوی عناصری هستند که قبلاً تحلیل شدهاند.
از این مقادیر عملکرد فیلترهای شکوفه ساخته می شود که در زیر به تفصیل توضیح خواهیم داد.
فیلترهای بلوم چگونه کار می کنند
بنابراین، هنگامی که فیلتر بلوم پیکربندی شد، میتوانیم بررسی کنیم که آیا یک عنصر بخشی از مجموعه است یا خیر. برای دستیابی به این هدف، فرآیندی که باید دنبال شود با ارسال داده های مورد نظر به الگوریتم فیلتر بلوم آغاز می شود. یعنی داده ها را از سیستم می گیریم و با استفاده از توابع هش سیستم پردازش می کنیم. این توابع هش در نتیجه دو موقعیت را برمی گرداند.
این هشها و موقعیتهایی که در نتیجه آنها برمیگردانند، ذخیره میشوند و به دادههایی که باعث ایجاد آن میشوند مرتبط هستند. بنابراین، فیلتر به جمعآوری اطلاعات، اعمال توابع هش برای آنها و ذخیره نتایج عملکرد آنها ادامه میدهد. با این حال، این فرآیند دارای یک روش اضافی است که کارایی آن را به حداکثر می رساند و زمان پاسخگویی سیستم هایی را که این نوع فیلتر را روی ساختار خود اعمال می کنند، بهبود می بخشد.
ابتدا، اگر دادههایی که به فیلتر منتقل شدهاند از توابع هش عبور کرده و موقعیتهایی را با مقادیری غیر از ۰ برمیگردانند، عنصر در داخل مجموعه است. این چیزی است که به عنوان مثبت شناخته می شود که نشان دهنده وجود آن عنصر در مجموعه است. همچنین ممکن است هش ها نتایج را با مقادیر متفاوت برگردانند.
برعکس، اگر یک یا هر دو موقعیت مقدار ۰ را نشان دهند، قطعاً مورد در مجموعه نیست. وضعیت دیگری که توسط الگوریتم پیش بینی شده و به آن منفی یا مثبت کاذب می گویند. این نتیجه قطعی است زیرا فیلترهای بلوم هرگز منجر به منفی کاذب نمی شوند. به عبارت دیگر، اگر الگوریتم فیلتر بلوم منفی یا مثبت کاذب را تشخیص دهد، این اطلاعات قطعاً در مجموعه داده های تجزیه و تحلیل شده نیست.
از سوی دیگر، هنگام پیکربندی فیلتر بلوم، تعیین تعداد بیت ها و توابع هش که اعمال می شود بسیار مهم است. از آنجایی که هر چه تعداد توابع هش بیشتر باشد، نسبت خطا بسیار کاهش می یابد، بنابراین احتمال داشتن نتایج مثبت کاذب کمتر خواهد بود. به همین ترتیب، هنگامی که مجموعه بیت فیلتر بلوم به طور کامل پر شد، داده های وارد شده قابل حذف نیستند. این کار به منظور عدم ظهور منفی کاذب در فیلتر.
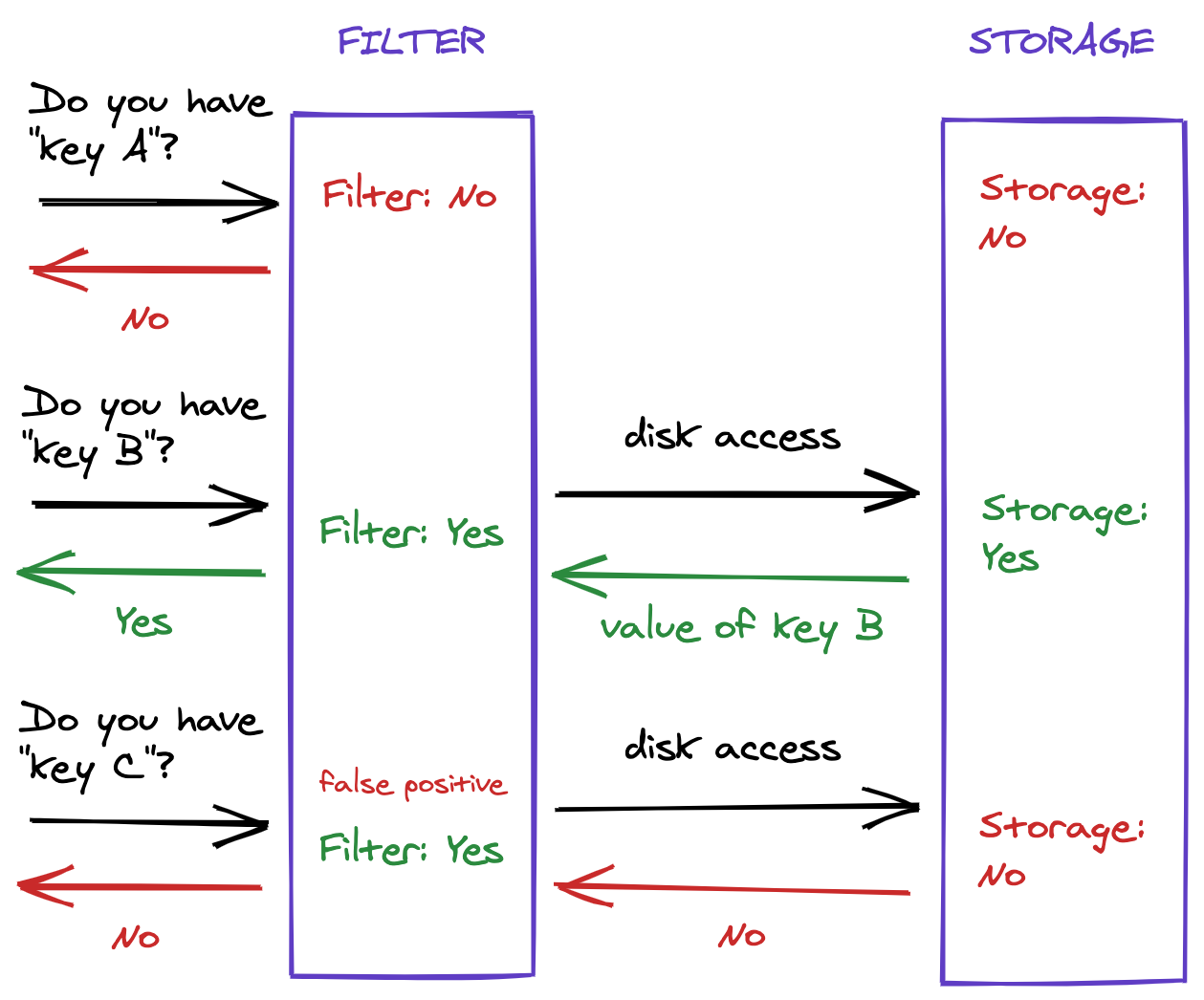
اهمیت نکات مثبت کاذب و منفی در فیلترهای بلوم
اهمیت مثبتکاذب و منفی فیلترهای بلوم در کارایی آن است. همانطور که قبلاً اشاره کردیم، فیلترهای بلوم طوری برنامه ریزی شده اند که هر دو حالت را در نظر بگیرند. و در صورت بروز آنها می توانیم اقدامات مقتضی را برای پاسخگویی مناسب انجام دهیم.
به عنوان مثال، اگر ما با یک سیستم ذخیره سازی داده برای تولید حافظه پنهان کار می کنیم، فیلتر بلوم کمک بزرگی به ما می کند. این به این دلیل است که هر بار که سیستم یک داده را دریافت می کند، کاری که باید انجام دهیم این است که بررسی کنیم آیا داده های گفته شده در داده هایی که در حافظه پنهان ذخیره کرده ایم هست یا خیر. بنابراین اگر این داده ها را وارد کنیم و فیلتر bloom یک منفی یا مثبت کاذب برگرداند، می توانیم مطمئن باشیم که این داده ها در مجموعه اطلاعاتی که مدیریت می کنیم نیست. و در آن مرحله، میتوانیم این دادههای جدید را در حافظه پنهان ذخیره کنیم تا بتوانیم سریع و کارآمد به آن دسترسی داشته باشیم.
برعکس، اگر فیلتر بلوم مثبت شود، میتوانیم به سادگی ذخیره اطلاعات را کنار بگذاریم و با آنچه در حافظه پنهان داریم کار کنیم، دسترسی بهتری به اطلاعات و در نتیجه صرفهجویی در منابع محاسباتی ارزشمند داریم.
این نوع عملیات با نرم افزاری که ما روزانه استفاده می کنیم غریبه نیست. به عنوان مثال، مرورگرهای وب از حافظه نهان ذخیره شده در هارد دیسک های ما استفاده می کنند تا در مقایسه با مشاوره آنلاین چنین داده هایی، به سرعت به منابع خاصی دسترسی پیدا کنیم. پایگاه های داده سرور و سایر سیستم هایی که حجم زیادی از داده ها را مدیریت می کنند نیز از فیلترهای بلوم یا الگوریتم های مشابه برای بهبود کارایی پاسخ ها و پردازش داده ها استفاده می کنند.
توابع هش در داخل فیلترهای بلوم
هنگام پیکربندی فیلتر بلوم، باید از توابع هش مستقل و به طور مساوی استفاده شود. این توابع هش اجازه می دهد تا یک شناسه به هر نوع داده اختصاص داده شود، که می تواند برای نمایه سازی یا مقایسه داده های گفته شده در یک مجموعه استفاده شود.
وقتی در مورد توابع هش صحبت می کنیم، در مورد SHA-256، MD5 یا توابع دیگری مانند CRC32 صحبت می کنیم. با این حال، در فیلترهای بلوم باید مراقب باشید. استفاده از بسیاری از توابع هش امنیت را افزایش می دهد، اما همچنین آن را پیچیده تر و وقت گیرتر می کند، بنابراین توابع باید به گونه ای انتخاب شوند که قابلیت های آنها به طور کامل مورد بهره برداری قرار گیرد.
از سوی دیگر، مشخصه یک طرفه توابع هش اجازه می دهد که یک شناسه را بتوان از یک عنصر یا داده تعیین یا ایجاد کرد، اما فرآیند مخالف را نمی توان انجام داد. بنابراین اگر کاربر یک شناسه را کشف کند، نمی تواند بداند داده ها یا عناصر مربوط به آن چیست.
مزایا و معایب استفاده از فیلتر بلوم
مزایای
- فیلترهای بلوم، با ذخیره نکردن مجموعه داده به این صورت، از نظر استفاده از فضای ذخیره سازی کارآمدتر هستند . از آنجایی که آنها فقط در صورتی ذخیره می کنند که اطلاعات یا عنصری در فیلتر بلوم وجود داشته باشد یا نباشد.
- به همین ترتیب، این ویژگی اجازه می دهد تا تأیید داده ها یا عناصر را بسیار سریعتر و کارآمدتر انجام دهید . اگرچه باید این را نیز در نظر گرفت که هر چه تعداد توابع هش بیشتر باشد، زمان مورد نیاز فیلتر بلوم برای تأیید وجود عناصر یا دادهها بیشتر است.
- مانند فیلترهای بلوم از مفهوم هش یک طرفه استفاده می کنند. اگر کاربر به آنها دسترسی پیدا کند، نمی تواند مستقیماً از هیچ یک از اطلاعات موجود در این فیلترها مطلع شود.
معایب
- این ابزارها داده های تایید شده را بر نمی گرداند . در عوض آنها فقط اجازه می دهند بررسی کنند که آیا احتمالاً وجود دارند یا خیر.
- وقتی نتایج مثبتی دارید، فقط می توانید فرض کنید که آنها احتمالاً درست هستند. هیچ اطمینان کاملی وجود ندارد که داده های مثبت بخشی از بسته است. برخلاف آنچه در صورت حصول نتایج منفی اتفاق می افتد. جایی که می توانید پاسخ یا نتیجه قطعی نهایی داشته باشید.
- هنگام طراحی فیلتر بلوم، صرف نظر از اینکه چند بیت یا میلیون بیت باشد، باید یک اندازه به آن اختصاص داد. هنگامی که یک اندازه تعیین می شود، بیشتر از آنچه قبلاً تعیین شده بود کاهش یا رشد نخواهد کرد. بنابراین، برای اینکه فیلتر بلوم کارآمد باشد، باید از قبل مشخص باشد که چه مقدار داده اضافه خواهد شد. بنابراین اگر این اطلاعات ناشناخته باشد، احتمالاً فیلتر بلوم با موارد بسیار کمی طراحی می شود که در مدیریت اطلاعات مورد نظر مؤثر نباشد. یا ممکن است یک فیلتر بلوم بسیار بزرگ طراحی شده باشد که به فضای ذخیره سازی بسیار بزرگی نیاز دارد تا حجم کمی از اطلاعات مورد استفاده قرار گیرد. که منجر به اتلاف فضا می شود.
فیلترهای بلوم برای عملکرد بهتر بلاک چین و خدمات مرتبط با آن عالی هستند. در مورد فیلترهای بلوم، آنها این امکان را برای SPV ها فراهم می کنند تا سریعتر همگام شوند تا تراکنش را در چند ثانیه تأیید کنند. این همچنین تأثیر زیادی بر میزان انتقال اطلاعات از طریق شبکه دارد، مصرف داده شما را کاهش می دهد و کارایی استفاده از پهنای باند شبکه را بهبود می بخشد.
موارد استفاده فیلترهای بلوم
ارزهای دیجیتال: بیت کوین و اتریوم
سیستم بیت کوین از فیلترهای بلوم برای افزایش سرعت همگام سازی کیف پول یا کیف پول SPV استفاده می کند . که به آنها اجازه می دهد فقط تراکنش هایی را که می خواهند به روز رسانی های سیستم را برای آنها دریافت کنند، مشخص کنند. تشکیل مجموعه ای از تراکنش ها که می تواند به گره های کامل شبکه منتقل شود. در آنجا می توانید از طریق این فیلترها تأیید کنید. سپس دریافت تاییدیه اضافه شدن یا نبودن این مجموعه تراکنش ها به زنجیره. نیازی به مدیریت یک کپی کامل از بلاک چین نیست. در بیت کوین این عملکرد توسط بلوک های فشرده ذکر شده در BIP-158 تغییر می کند.
به نوبه خود، شبکه اتریوم از فیلترهای بلوم به عنوان مکانیزمی استفاده می کند که از طریق آن می توانید لاگ ها را در بلاک چین خود پیدا کنید . بنابراین با پیاده سازی این فیلترها می توانید به راحتی وقایع رخ داده در سیستم اتریوم را جستجو کنید. بدون بارگذاری بیش از حد آن توسط دست زدن به اطلاعات بیش از حد. ساخت برنامه ها می تواند این اطلاعات را بسیار کارآمدتر مدیریت کند. در حالی که به فضای ذخیره سازی زیادی نیاز ندارد. از آنجایی که با فیلترهای بلوم نیازی به ذخیره داده هایی نیست که می توانند در سیستم تکرار شوند.
در اتریوم، زمانی که یک بلوک تولید و تأیید میشود، آدرس قرارداد و فیلدهای فهرستشده رکوردها به فیلتر بلوم اضافه میشوند. این فیلتر در هدر بلوک قرار دارد. بنابراین اگر برنامهای بخواهد همه ورودیهای رجیستری را پیدا کند، گره فقط باید هدر را اسکن کند. بنابراین می توانید تشخیص دهید که داده های مورد نیاز وجود دارد یا خیر. بنابراین این عناصر برای صرفه جویی در فضای ذخیره سازی به این بلوک اضافه نمی شوند.
شبکه ها و کانال های اطلاع رسانی
اجرای مهم دیگر فیلترهای بلوم به شبکه ها یا کانال های اطلاعاتی اجازه می دهد تا توصیه های مقاله را به کاربران ارائه دهند. اجازه نمی دهد تکرار شوند. یعنی می توانید دریابید که کاربر چه مقالاتی را خوانده است و چه مقالاتی را که هنوز ندیده است.
به همین ترتیب، مراکز داده بزرگ و مراکز توزیع محتوا (CDN) از فیلترهای بلوم برای به حداکثر رساندن کارایی ذخیره سازی داده ها و استفاده از شبکه استفاده می کنند و از تبدیل شدن عناصر تکراری یا کم استفاده به بخشی از سیستم خود با بارگذاری بیش از حد آنها جلوگیری می کنند. این شامل شرکت هایی مانند Akamai، Namecheap CDN، Fastly یا Cloudflare می شود.